3.7 KiB
Data Maturity Model
Maslow hierarchy of needs, data version:

Data collection
You get data from places.
You place it as is in some staging area.
Data wrangling
Cleaning stuff up, deduplicating, yadi yada.
Data integration
Place everything together nicely in the same place in a usable model.
ETL
ETL made sense before. Storage was expensive and you only wanted to load the strictly necessary data into the target DWH.
But this comes with problems:
- You have a lot of statefulness.
- Debugging and testing pipelines is a pain in the ass.
- You need to do transformations outside of your target database.
- Schema changes were nightmares.
ELT is the new shiny toy:
- We read raw data from source system and load it into our DWH/Data Lake.
- We do our transformations in the target system.
- Schema changes become much more manageable.
Datawarehouses and data lakes
Datawarehouse
DWH -> Any database that:
- We use to ground our BI and reporting on.
- Optimized for reads.
- Typically structured in facts and dimensions.
Data Lake
Decouple storage from compute. Use S3/Blob Storage/Hadoop HDFS for storage. Everything gets stored as files. Use a separate query engine, like Athena, Trino, Spark.
Data Lakehouse
Just use both. A data lake with some DWH layer on top. Pretty much, a swamp of files with some governance, modelling tool sitting on top of it to control access and ease queries.
The modern data stack
Cheaper storage -> We don't mind duplicating data more. Faster networking -> We can spread work across more machines and decouple things like storage and processing. We can distribute workloads with distributed storage and compute.
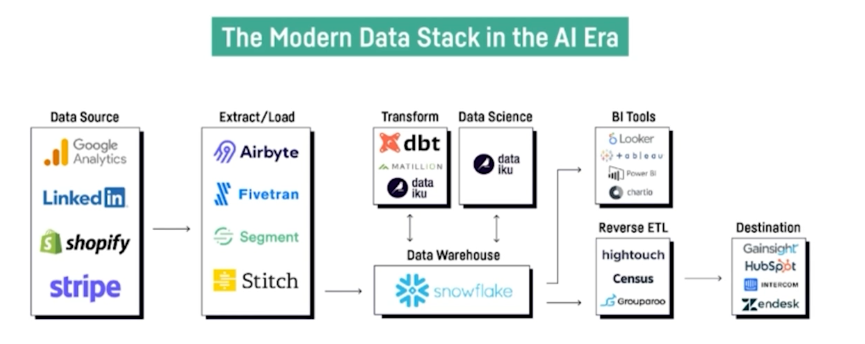
dbt makes sense nowadays because the modern data stack makes transformations within the datawarehouse.
Slowly Changing Dimensions
- The issue comes when a dimension changes in a way that would break referential integrity.
- Sometimes, old data can be thrown away. Sometimes, not.
- There are 4 SCD types.
- SCD 0 - Retain original
- Do not update data in the DWH. Source data and DWH gets out of sync.
- You do this when you don't care about the dimension truly.
- Example: Fax numbers when fax is not used anymore.
- SCD 1 - Overwrite
- Overwrite new values in DWH. Old values go away.
- We only care about the new state. We don't need the history.
- SCD 2 - Add new row
- Add new raw with
start_dateandend_datefields to indicate which values should be looked at depending on time. - Used when full historical view is important.
- Increases amount of data stored.
- Add new raw with
- SCD 3 - Add new attribute
- Keep current attribute value and previous value
- It only keeps the previous type at most
- Intermediate approach between SCD2 and SCD1
- SCD 0 - Retain original
dbt overview
- dbt takes care of the T in ETL/ELT.
- dbt works within the datawarehouse and with SQL.
- Why not use raw SQL and that's it? Because dbt brings good software practices like modularity, version control, reusability, testing, documentation and such to SQL swamps.
Case
- ELT in Airbnb.
- Data from insideairbnb.com/berlin/
- The project will use snowflake as a DWH and preset (managed superset) as a BI tool.
dbt project structure
dbt_project.yml: header of the project, with stuff like versioning, the default profile for the project, the paths to different folders, etc.
This is a pic of the data flow we are going to build: 
Sources and seeds
Seeds are local files that you upload to a DWH from dbt. You place them as CSVs in the seeds folder.
Sources are an abstraction layer on top of the input tables.